What Is RAG (Retrieval-Augmented Generation)? An Enterprise Guide for 2026
Large language models are powerful, but on their own they have two stubborn problems: they only know what they were trained on, and they will confidently make things up when they don't know the answer. For a consumer chatbot that's annoying. For an enterprise—where answers feed real decisions, customers, and compliance—it's a deal-breaker. Retrieval-Augmented Generation (RAG) is the architecture that fixes both problems, and it's why so many serious AI systems in 2026 are built on it.
This guide explains what RAG is in plain language, how it works step by step, why enterprises are standardizing on it, and what it takes to build one well.
What is Retrieval-Augmented Generation?
RAG is a technique that connects a language model to an external, trusted source of information—your documents, databases, or knowledge base—so the model answers using real data it just looked up, instead of relying only on its training memory.
Think of it as the difference between an exam taken from memory and an open-book exam. In a RAG system, the model gets to "open the book" (your data) at the moment of the question, find the most relevant pages, and write its answer based on what it found. The result is responses that are more accurate, more current, and—crucially—traceable back to a source.
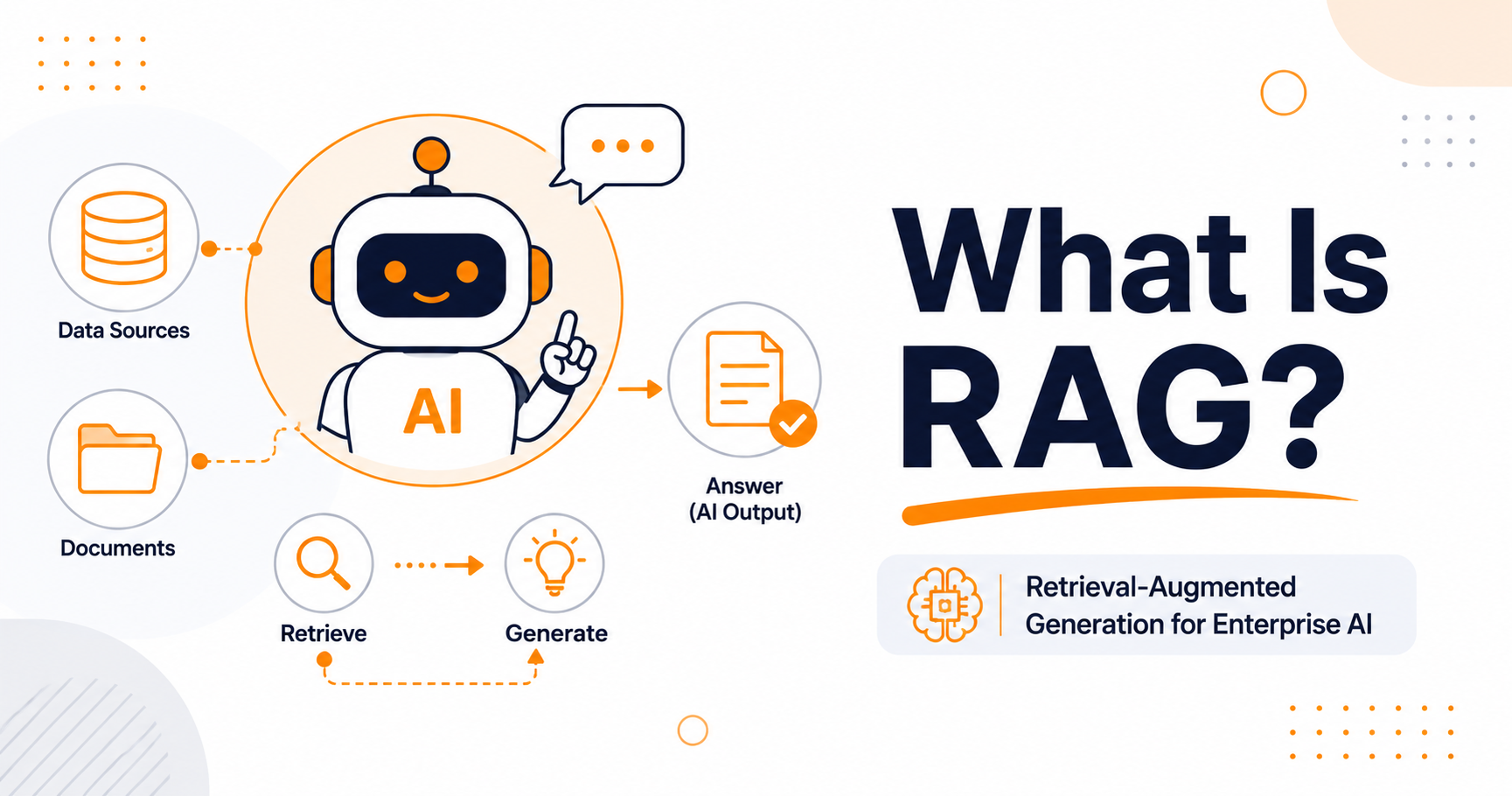
How RAG works, step by step
Every RAG system follows the same core loop. The name itself describes it: Retrieve, Augment, Generate.
- Retrieve: When a user asks a question, the system searches your knowledge base for the most relevant pieces of information. This usually happens through a vector search that matches meaning, not just keywords.
- Augment: The retrieved snippets are added to the prompt that gets sent to the language model, giving it the exact context it needs to answer.
- Generate: The model writes a natural-language answer grounded in that supplied context, and can cite which sources it used.
The user experiences a single smooth answer. Behind the scenes, the system has done a focused lookup and handed the model the right facts at the right moment.
Why RAG is becoming the backbone of enterprise AI
It dramatically reduces hallucinations
When a model is given the relevant facts and told to answer from them, it has far less reason to invent things. Grounding answers in retrieved data is the single most effective way to make enterprise AI trustworthy.
It keeps answers current
Retraining a model every time your data changes is slow and expensive. With RAG, you simply update the knowledge base—new policy, new product, new price—and the next answer reflects it instantly. No retraining required.
It respects data privacy and control
Your proprietary data stays in your own systems and is retrieved only when needed, rather than being baked permanently into a model. That separation makes governance, access control, and compliance far easier to manage.
It's cheaper than fine-tuning for most use cases
Fine-tuning bakes knowledge into model weights and must be redone as information changes. RAG keeps knowledge in a searchable store you can edit cheaply, making it the more practical choice for most fast-moving business data.
It builds trust through citations
Because RAG knows exactly which documents it used, it can show its sources. Users can verify answers, and teams can audit them—essential for legal, financial, and healthcare contexts.
RAG vs fine-tuning: which do you need?
These are often framed as rivals, but they solve different problems and are frequently used together.
- Use RAG when you need the model to know facts—company knowledge, documentation, policies, product data—especially if that information changes often.
- Use fine-tuning when you need to change the model's behavior, tone, or format—how it responds, not what facts it knows.
A common enterprise pattern is fine-tuning a model for a consistent voice and structure, then layering RAG on top so it always answers from up-to-date, trusted data.
The core components of a RAG system
Building a production RAG pipeline means assembling a handful of moving parts:
- Data ingestion: Pulling in your source content—PDFs, web pages, tickets, wikis, database records.
- Chunking: Splitting documents into sensible, bite-sized passages so retrieval is precise.
- Embeddings: Converting each chunk into a numerical vector that captures its meaning.
- Vector database: Storing those vectors so similar meanings can be found quickly—popular options include Pinecone, Weaviate, Milvus, Qdrant, and Chroma.
- Retriever: Finding the most relevant chunks for a given query.
- LLM: Generating the final answer from the retrieved context.
- Orchestration: The glue that connects these steps—often built with frameworks like LangChain or LlamaIndex—exchanging data as JSON between services and APIs.
Because so much of a RAG pipeline passes structured data between services, developers spend real time reading and debugging API payloads. Tools like our JSON Formatter and JSON Viewer make those responses readable, and the JSON Validator helps you catch malformed payloads before they break a pipeline.
Where enterprises use RAG today
- Customer support: Assistants that answer from your real help docs and policies, not guesses.
- Internal knowledge: Employees query scattered wikis, HR policies, and runbooks in plain language.
- Search and research: Analysts get synthesized answers with citations instead of a list of blue links.
- Compliance and legal: Teams query large document sets and trace every answer back to its source.
Common challenges and best practices
RAG is powerful, but "garbage in, garbage out" applies hard. A few principles separate reliable systems from frustrating ones:
- Invest in data quality. Clean, well-structured source content is the biggest driver of good answers.
- Get chunking right. Chunks that are too big add noise; too small lose context. Tune to your content.
- Measure retrieval quality. If the wrong passages are retrieved, even the best model will answer badly. Evaluate retrieval separately from generation.
- Build evaluation in from day one. Track accuracy, groundedness, and citation correctness, not just vibes.
- Secure your context. Enforce access control so the retriever never surfaces data a user shouldn't see.
Frequently asked questions
Is RAG only for large companies?
No. RAG scales down well—even a small documentation site or support knowledge base benefits. The architecture is the same; only the volume changes.
Does RAG replace fine-tuning?
Not usually. RAG supplies up-to-date knowledge; fine-tuning shapes behavior and style. Many systems use both together.
What data can a RAG system use?
Almost any text-based source: documents, PDFs, web pages, support tickets, wikis, and database records. The key is that it's cleaned, chunked, and indexed for retrieval.
Final thoughts
RAG has become the backbone of enterprise AI because it solves the two problems that matter most in real deployments: accuracy and freshness. By letting models answer from your own trusted, current data—and cite their sources—RAG turns impressive demos into systems businesses can actually rely on. If you're planning AI in 2026, RAG isn't an optional add-on; it's the foundation.
Building tools or content around AI and the web? Explore our full set of SEO and developer tools, and tighten up any pages you publish with our on-page SEO checklist.